Vous avez branché Claude API sur un assistant interne il y a un mois. Ça tourne, les utilisateurs sont contents, vous regardez la facture en fin de mois. Surprise : vous êtes à 2 ou 3x ce que vous aviez budgété. Pas catastrophique, mais bien plus que prévu.
Le coupable est presque toujours le même. Vous envoyez le même contexte (prompt système, documentation, historique de conversation) à chaque appel. Et vous le payez plein tarif à chaque fois.
C'est exactement ce que le prompt caching d'Anthropic est venu corriger.
Pourquoi le prompt caching existe
Les LLM sont stateless. À chaque requête, le modèle reparse l'intégralité de votre prompt depuis zéro, comme s'il vous découvrait. C'est conceptuellement simple, mais en facture, c'est brutal.
Sur un agent ou un chatbot avec un long prompt système (instructions détaillées, persona, exemples few-shot, documentation injectée), 80 à 90% du nombre de tokens par requête est strictement identique d'un appel à l'autre. Vous payez ce contexte fixe à chaque tour, alors qu'il n'a pas bougé d'un caractère.
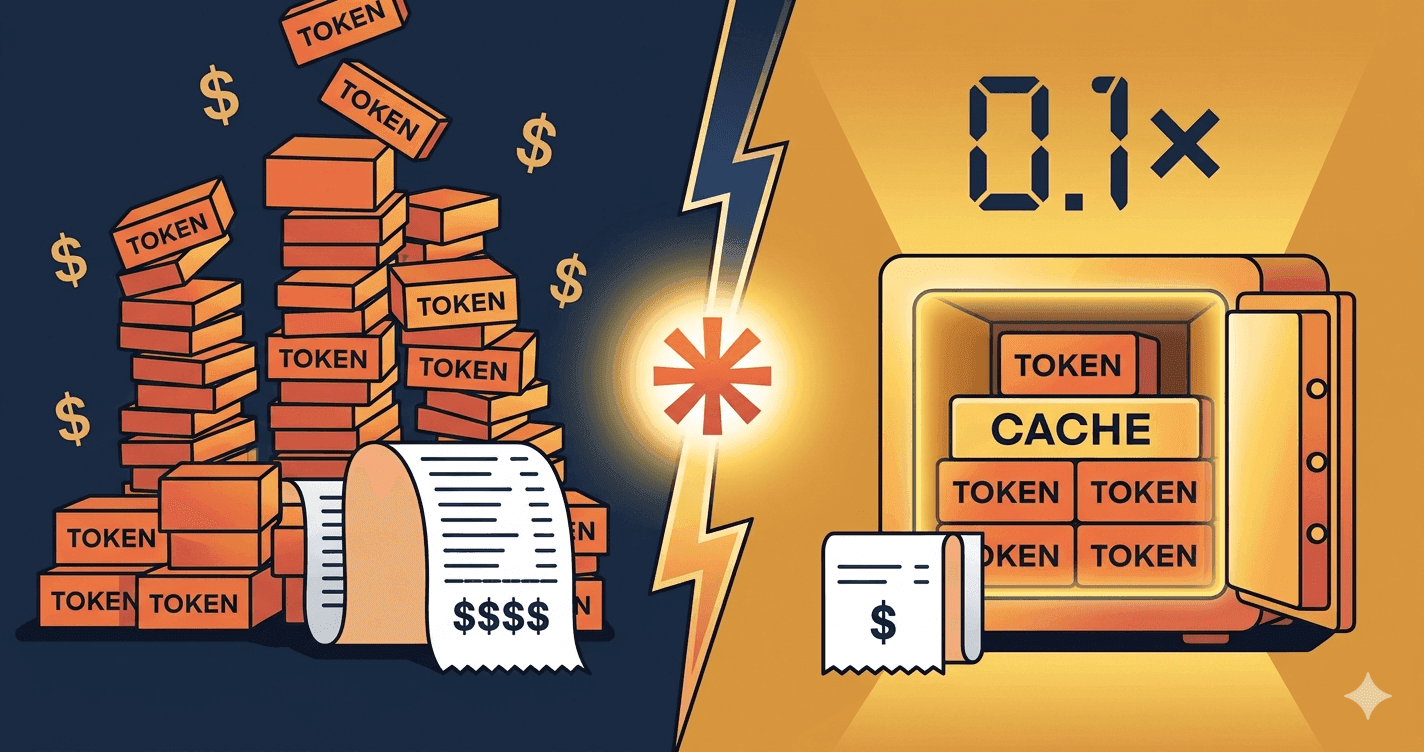
Anthropic a regardé ce problème et a posé une grille tarifaire qui change la donne. La lecture cache (cache hit) se facture à 0.1x le prix d'entrée normal. L'écriture cache se facture à 1.25x pour un TTL de 5 minutes, ou 2x pour un TTL de 1 heure.
Le calcul est vite fait. Si 80% de votre prompt est cacheable et que vous faites 10 appels dans une conversation, vous divisez vos coûts d'entrée par un facteur 3 à 5. Sans changer votre code, sans dégrader la qualité.
Le prompt caching, c'est ce qui fait passer un POC Claude de "trop cher à grande échelle" à "rentable en prod".
Comment ça marche concrètement
Le mécanisme tient en quelques règles précises.
Vous pouvez poser jusqu'à 4 points cache_control par requête. Chaque point dit à Claude "tout ce qui précède doit être mis en cache". Le TTL par défaut est de 5 minutes. Vous pouvez le pousser à 1 heure via l'en-tête beta extended-cache-ttl-2025-04-11, au prix d'une écriture plus chère.
L'ordre est imposé : outils, puis prompt système, puis messages. Vos blocs cacheables doivent être au début du prompt. Tout ce qui est dynamique (la question de l'utilisateur, les données spécifiques de la requête) vient après.
Il y a un seuil minimum : 1024 tokens pour Claude Sonnet et Opus, 2048 pour Haiku. En dessous, le cache ne se déclenche pas.
Un cache miss veut dire que vous repayez l'écriture. C'est important à intégrer : si votre cache expire entre deux requêtes parce que personne n'a parlé pendant 6 minutes, le prochain appel paiera la pénalité d'écriture. La fenêtre de 1 heure devient pertinente quand vous savez que votre agent va tourner sur la journée mais avec des creux entre deux interactions.
Les 4 cas où ça vaut vraiment le coup
Chatbot avec long prompt système
Vous avez un assistant interne avec 5000 tokens d'instructions, de persona, et d'exemples few-shot. À chaque message utilisateur, ce bloc est identique. Vous le mettez dans le prompt système avec un point cache_control à la fin, et vous arrêtez de le payer 100 fois par jour.
RAG sur session
Vous chargez 30 000 tokens de documents source au début d'une session de chat (procédures internes, base de connaissances, contrats). L'utilisateur enchaîne 15 questions sur ces documents. Sans cache, vous payez 30 000 tokens de lecture x 15 appels. Avec cache, vous payez l'écriture une fois, puis 15 lectures à 0.1x.
Agent multi-tour
Un agent qui utilise des outils voit son contexte grossir à chaque tour : la liste des outils, le prompt système, et l'historique des actions précédentes. Le préfixe (outils + prompt système) reste stable. L'historique aussi, jusqu'au dernier tour. Vous posez des points de cache stratégiques sur ce qui est stable, et le modèle ne paie plus que l'écart du dernier tour.
Traitement par lot
Vous traitez 1000 documents avec le même modèle de prompt (extraction d'entités, classification, résumé). Le modèle fait 3000 tokens, le document varie. Vous cachez le modèle, vous itérez sur les documents. Sur 1000 appels, l'économie devient massive.
Quand ça ne vaut PAS le coup
Si votre prompt fait moins de 1024 tokens, le cache ne se déclenchera pas. Pas la peine d'essayer.
Si vos requêtes sont vraiment ponctuelles, sans personne qui revient dans la fenêtre de 5 minutes ou 1 heure, vous paierez l'écriture sans jamais profiter d'une lecture. Le cache devient un coût supplémentaire, pas une économie.
Si votre contenu dynamique se trouve en début de prompt (par exemple, vous injectez la date du jour avant le prompt système), tout ce qui suit n'est pas cacheable. Le cache se base sur un préfixe identique au token près.
Les 3 pièges classiques
Le premier, c'est de mettre du contenu dynamique avant le point de cache. Vous insérez un horodatage, un identifiant utilisateur, ou une variable qui change à chaque appel dans le bloc supposé cacheable. Résultat : le préfixe diffère à chaque requête, le cache n'est jamais touché. Vous payez l'écriture à chaque tour sans jamais lire.
Le deuxième, c'est d'oublier les conditions de la fenêtre 1 heure. C'est en beta, ça nécessite un en-tête explicite, et l'écriture coûte 2x au lieu de 1.25x. Sur un usage où la fenêtre 5 minutes suffit, vous payez plus cher pour rien. Faites le calcul avant.
Le troisième, c'est de croire que le cache va vous faire gagner de la latence. Le gain principal du prompt caching, c'est le coût, pas la vitesse. Il y a bien une réduction du temps de premier token sur les cache hits, mais ne vendez pas ce projet en interne en promettant un assistant deux fois plus rapide. Vendez-le sur la facture qui devient soutenable.
Pour aller plus loin
Le prompt caching n'est pas un truc d'optimisation pour devs avancés. C'est ce qui fait passer un POC Claude de "trop cher à grande échelle" à "rentable en prod". Beaucoup d'équipes lâchent Claude au moment du calcul de coût, sans avoir activé la seule fonctionnalité qui rend l'économie viable.
Si vous voulez creuser comment positionner Claude dans votre architecture, direction la page consultant Claude freelance. Si vous hésitez encore entre Claude et GPT en amont du choix technique, ce comparatif pose la question avant de parler caching.
Parlons-en 30 minutes si vous avez un POC Claude qui marche techniquement mais qui coince côté budget. Souvent, le caching seul suffit à débloquer la mise en prod.
Vous voulez l'implémenter chez vous ?
Si vous voulez un agent Claude construit avec le prompt caching activé dès le départ, pour que l'économie tienne à l'échelle avant la mise en prod.